I’m asked often to both describe Data Science and analytics in general and to discuss what differentiates our program. I end up throwing up a lot of words like Machine Learning Engineering, Artificial Intelligence, Data Engineer, and Full-Stack Data Scientist, and it quickly becomes clear that these terms and topics deserve further explanation. This blog post is an attempt to gather relevant links and provide our interpretation of some of these terms. One of the most useful posts I’ve found is one that discussed a Type A versus a Type B data scientist. Our program produces students who can be hired as either Type A or Type B data scientists though they might naturally prefer one of the other (https://towardsdatascience.com/ode-to-the-type-a-data-scientist-78d11456019).
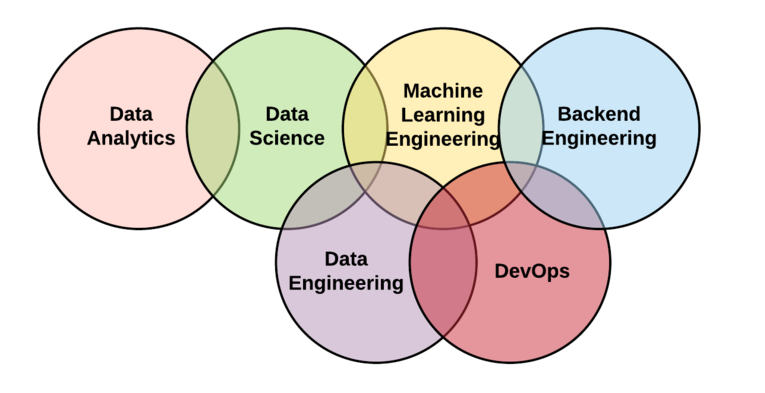
The first distinction to draw is to discuss how much computer science is contained within a curriculum. This is one of the main factors that drives the type of data scientist produced. Our program incorporates distributed computing, advanced database topics, programming (of course), and software engineering as a possible elective package. This means that all of graduates can use and develop advanced technical tools such as Apache Spark, Hadoop, BigQuery, MongoDB, etc, and even develop the next generation of these technologies. Now not all students feel as strongly about these skills of course, but everyone receives a foundation to contribute and support data science projects that require these methodologies. Here are some links for further reading:
- https://medium.com/@tomaszdudek/but-what-is-this-machine-learning-engineer-actually-doing-18464d5c699
- https://www.datacamp.com/community/blog/data-scientist-vs-data-engineer
The other equal pillar in our program is statistical or machine learning. We maintain a focus on these core skills so our graduates can perform high quality analytics and artificial intelligence driven machine learning. In other words, they can also be your ace “Type A” data scientist.